Category Archives: Academic
Technical Documentation
We have compiled on a single document our academic posts. Through these articles we aim at explaining the technology, from an academic point of view, and the way we have implemented it at Bheudek.

[Click to download]
For any question or further information you can contact us at info@bheudek.com.
View all Academic Posts.
View all Academic Posts.
Benefits of Automation in the World of FinTech
The financial industry is facing its greatest technological challenge: the FinTech phenomenon. Addressing this change, which involves many different areas and technologies, requires a comprehensive approach to prevent operational and technological chaos.
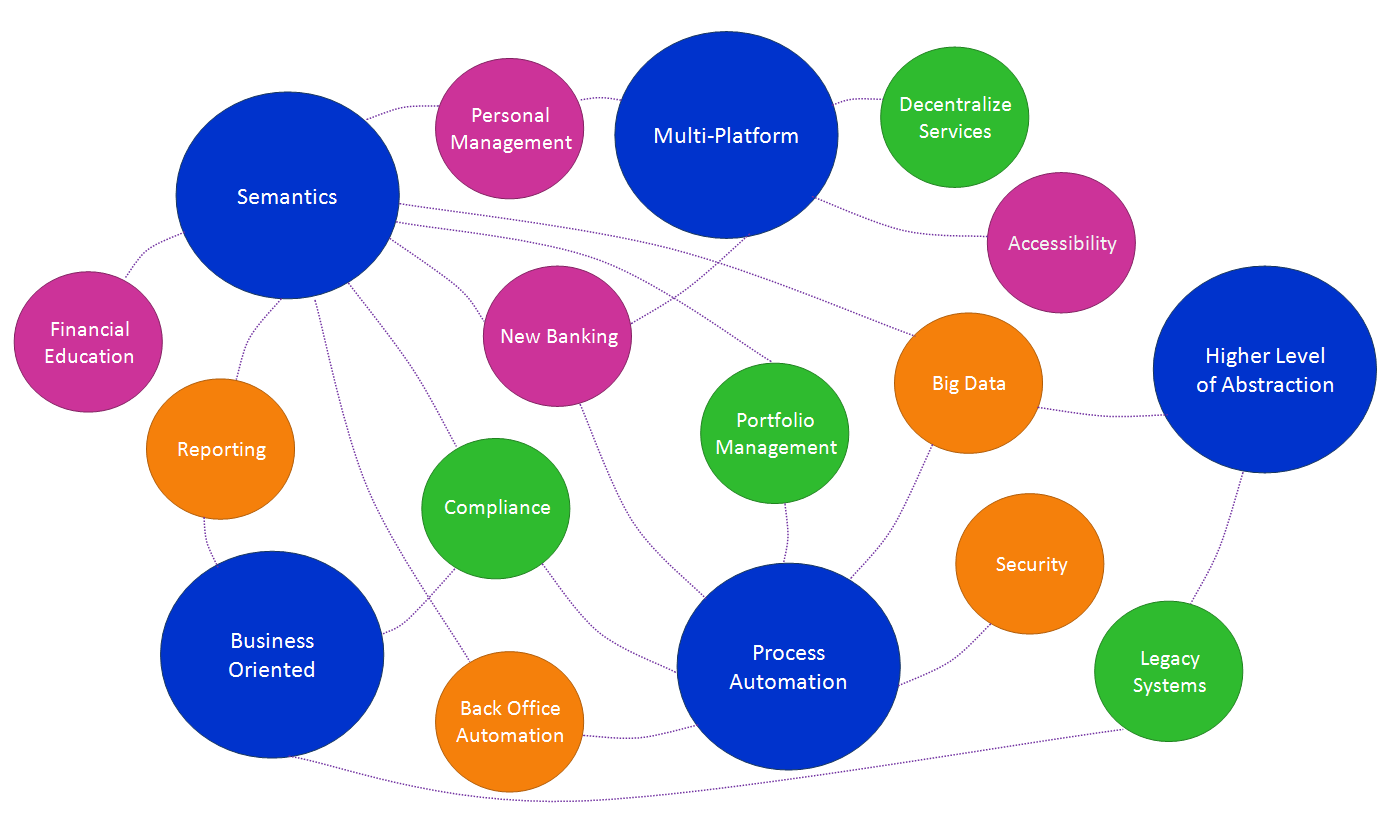
Given this scenario, automation is presented as the unified solution the problem requires. Features such as semantics and process automation can offer their benefits to the changes that will be performed in different areas: business services, online services and data management.
Given this scenario, automation is presented as the unified solution the problem requires. Features such as semantics and process automation can offer their benefits to the changes that will be performed in different areas: business services, online services and data management.
The financial industry is immersed in a process of technological renewal. The opportunities offered by new technologies and the emergence of new players, many of them coming from other industries (Google, Amazon, Apple ..), have forced the industry to make a move.
The FinTech phenomenon involves changes in many different areas with many different technologies. This leads to a complex scenario where the problem must be addressed from a global perspective, otherwise there is a risk of running into an operational and technological chaos.
New techniques in Software Automation suggest this methodology as a good solution to tackle the challenge.
The FinTech phenomenon involves changes in many different areas with many different technologies. This leads to a complex scenario where the problem must be addressed from a global perspective, otherwise there is a risk of running into an operational and technological chaos.
New techniques in Software Automation suggest this methodology as a good solution to tackle the challenge.
Software automation raises the technical solution to the conceptual level where operates the business. This higher point of view provides the more comprehensive and unified approach required to address FinTech changes.
From a technical perspective, software automation is based on the creation of more abstract programming languages which allows the automation of the technical details and gives the system more semantic richness. These languages are known as DSLs and the tool to manage them Language Workbench.
Benefits.
1.Process automation.
Working in a more abstract level allows not only the automation of technical process but also the automation of traditional business processes. Decision engines, risk based pricing, default prediction and fraud detection are examples of processes that can be improved under this perspective.
2.Semantics.
The new way of defining programming languages, based on the concepts that structure them, opens the door to Knowledge Representation. This discipline, a traditional field of artificial intelligence, is increasingly being applied to data processing (visualization, searching, analysis, decision making …) and in the future will be essential to any process of analysis and interaction, either with customers or with other systems. XBRL– eXtensible Business Reporting Language – and FIBO – Financial Industry Business Ontology – are examples of semantics applied to financial industry
3.Less technical complexity.
Again, the higher level of abstraction of the languages allows to solve, automatically, much of the technical details inherent to the different solutions. This automation of complexity results in quality, safety, standardization and other software features.
4.Multi-platform.
Having the control of programming languages, the same development can be translated into multiple platforms without having to perform a new project for each new device.
5.Business oriented.
Once the programming languages are closer to the business, developers can focus on providing a solution from the business point of view and not from a technical perspective. It also breaks down the traditional communication barriers between the development areas and the rest of areas of the company.
Enhanced areas.
FinTech is working on multiple areas in which the automation can provide advantages. We can group them into three main blocks: business services, online services and data management.
1.Business services.
Meeting customers’ new demands and productivity improvement are objectives that are moving the industry to act over their more traditional structures. Automation provides advantages on:
Benefits.
1.Process automation.
Working in a more abstract level allows not only the automation of technical process but also the automation of traditional business processes. Decision engines, risk based pricing, default prediction and fraud detection are examples of processes that can be improved under this perspective.
2.Semantics.
The new way of defining programming languages, based on the concepts that structure them, opens the door to Knowledge Representation. This discipline, a traditional field of artificial intelligence, is increasingly being applied to data processing (visualization, searching, analysis, decision making …) and in the future will be essential to any process of analysis and interaction, either with customers or with other systems. XBRL– eXtensible Business Reporting Language – and FIBO – Financial Industry Business Ontology – are examples of semantics applied to financial industry
3.Less technical complexity.
Again, the higher level of abstraction of the languages allows to solve, automatically, much of the technical details inherent to the different solutions. This automation of complexity results in quality, safety, standardization and other software features.
4.Multi-platform.
Having the control of programming languages, the same development can be translated into multiple platforms without having to perform a new project for each new device.
5.Business oriented.
Once the programming languages are closer to the business, developers can focus on providing a solution from the business point of view and not from a technical perspective. It also breaks down the traditional communication barriers between the development areas and the rest of areas of the company.
Enhanced areas.
FinTech is working on multiple areas in which the automation can provide advantages. We can group them into three main blocks: business services, online services and data management.
1.Business services.
Meeting customers’ new demands and productivity improvement are objectives that are moving the industry to act over their more traditional structures. Automation provides advantages on:
Decentralization. To perform the decentralization of services (call centers, back office…), their applications need to migrate to a web environment. This is a major challenge because the systems must keep the traditional desktop applications features: safety, speed and user-experience. Automation provides a more efficient way to develop Desktop Web Applications.
Portfolio management. The automation of processes provides a more streamlined management. On the other hand, the semantics allows a unified management of heterogeneous portfolios and the integration of external ones.
Compliance. Semantics, along with the use of business-oriented languages facilitate audit analysis processes and the deployment of its documents. Beside this, process automation is the best way to solve compliance issues.
Legacy systems. The higher level of abstraction provides a straightforward way to design interfaces with legacy systems.
Portfolio management. The automation of processes provides a more streamlined management. On the other hand, the semantics allows a unified management of heterogeneous portfolios and the integration of external ones.
Compliance. Semantics, along with the use of business-oriented languages facilitate audit analysis processes and the deployment of its documents. Beside this, process automation is the best way to solve compliance issues.
Legacy systems. The higher level of abstraction provides a straightforward way to design interfaces with legacy systems.
2.Online services.
The emergence of new devices, the improvement of communications and a new digital culture have made institutions open their doors in order to supply a more interactive management to their customers. Again automation provides benefits in this area:
The emergence of new devices, the improvement of communications and a new digital culture have made institutions open their doors in order to supply a more interactive management to their customers. Again automation provides benefits in this area:
Accessibility. Multi-platform can multiply the ways of interaction.
Financial education. Semantics gives the systems documentation and visualization capabilities facilitating its handling and understanding.
Personal Management. As a result of the previous points, the customer can perform a more personal management of their data and assets. As mentioned, the semantics play a major role in the interaction with the customer.
New Banking. Multi-platform, semantics and process automation enable new business lines such as personalized offers, payment platforms, crypto-currencies, proactive risk analysis and others.
Financial education. Semantics gives the systems documentation and visualization capabilities facilitating its handling and understanding.
Personal Management. As a result of the previous points, the customer can perform a more personal management of their data and assets. As mentioned, the semantics play a major role in the interaction with the customer.
New Banking. Multi-platform, semantics and process automation enable new business lines such as personalized offers, payment platforms, crypto-currencies, proactive risk analysis and others.
3.Data management.
A more interactive relation with the customer and the new methodologies to process that information have revolutionized traditional CRM techniques and the whole data management. Automation benefits next areas:
A more interactive relation with the customer and the new methodologies to process that information have revolutionized traditional CRM techniques and the whole data management. Automation benefits next areas:
Back office automation. The automation of back office means the automation of its workflows. The possibilities powered by semantic to design “smarter” decision engines, together with process automation, are key lines to achieve this goal.
Reporting. Semantics is increasingly being a part of reporting. XBRL is a good example.
Security. Process automation enhances the security in data processing.
Big Data. We can summarize – this point would require an entire article – that semantics, process automation and a higher level of abstraction allows, on one hand, to handle the variability of the data and, on the other, mitigate the risks associated with the unstructured schemas of Big Data.
Reporting. Semantics is increasingly being a part of reporting. XBRL is a good example.
Security. Process automation enhances the security in data processing.
Big Data. We can summarize – this point would require an entire article – that semantics, process automation and a higher level of abstraction allows, on one hand, to handle the variability of the data and, on the other, mitigate the risks associated with the unstructured schemas of Big Data.
Conclusion.
The financial sector is facing one of the greatest technological challenges in its history, involving changes in many different areas with many different technologies.
Software automation provides the global and unified approach required in this scenario, otherwise, individual approaches can lead the companies to a technological landscape very hard to manage.
Desktop Web Applications
Beyond marketing or digital identity, companies increasingly find the web as the way to enhance their productivity and services: decentralize management (back offices) or give the customers an online service are examples of it.
Although the Web was not originally designed for a dynamic and bidirectional interaction, the emergence of new technologies and the improvements in modern browsers, allow us to design applications ever closer to traditional desktop applications.
These web applications are different from web pages and web applications (e-commerce, for example) because their users need a more continuous, long and agile interaction with the system. For example, a call center user (customer service, technical service, collection management and others).
Requirements for a desktop web application
Although the Web was not originally designed for a dynamic and bidirectional interaction, the emergence of new technologies and the improvements in modern browsers, allow us to design applications ever closer to traditional desktop applications.
These web applications are different from web pages and web applications (e-commerce, for example) because their users need a more continuous, long and agile interaction with the system. For example, a call center user (customer service, technical service, collection management and others).
Requirements for a desktop web application
- Keyboard. It is essential that the application can be governed by the keyboard and not only by the mouse. Tab, enter, arrows and others keys.
- Performance. An appropriate speed is required not only for a good user experience but also for productivity matters.
- Security. These applications deal with very sensitive data.
- No blinking effect. Content loading must be partial and dynamic. Continuous refreshment of the whole page produces an uncomfortable and unhealthy effect.
- Nice and standard layout. Content must be clean and never overloaded (kitsch).
Tips to meet them
- SPA pattern (Single Page Application). The app is a single initial page where further content is loaded dynamically. It allows us to implement policies such as: initial loading of files (js, css, images, etc), shared session control, increase processing on the client, etc..
- Standard layout across the whole application. The screens, buttons, tabs, data grids and other controls should have a common look&feel.
- JavaScrtipt Framework. Required to standardize the interface and provide it with the services to manage controls and windows. For security and adaptability reasons, the best choice for a framework is in-house development and single-object encapsulation.
- Handle keyboard events. The framework must provide this feature.
- AJAX. Dynamism.
- Minimize network traffic. Data transferred from the server should be as few as possible, even if it means more processing on the client side. Standards as JSON are recommended.
- Modal windows. They improve the user experience and the application dynamism.
- Use sprite images. Load all images on a single connection.
A UI automated development and a powerful js framework is the best way to achieve these goals.
Conclusion
 Whenever we deal with desktop applications, we must meet some strict requirements, as they are tools in which users will spend much of their time.
Whenever we deal with desktop applications, we must meet some strict requirements, as they are tools in which users will spend much of their time.
New devices may appear and also new ways to interact with systems, but when it comes to interaction, traditional requirements as keyboard, performance, safety and user experience are a must have.
View all Academic Posts.
Conclusion
 Whenever we deal with desktop applications, we must meet some strict requirements, as they are tools in which users will spend much of their time.
Whenever we deal with desktop applications, we must meet some strict requirements, as they are tools in which users will spend much of their time.New devices may appear and also new ways to interact with systems, but when it comes to interaction, traditional requirements as keyboard, performance, safety and user experience are a must have.
View all Academic Posts.
Summary of the Methodology
Throughout various posts we have been showing the different elements in software automation and theirs benefits. Here we summarize this methodology:
- Software Automation. Introduction. . First approach to the technology.
- Why code generation? . Explains the reasons to choose code generation in order to improve the software development process.
- Best Practices in Code Generation . Once we know what it is, we show some tips to generate code properly.
- 10 Benefits of Code Generation . List of benefits.
- DSLs . Following the path of automation, we explain what are Domain Specific Languages (DSL) and their benefits. The DSLs are necessary if we want our automation process to reach the highest level.
- Language Workbench . In order to design and use DSLs we need tools that provide these services. These tools are technically known as Language Workbenches, and they can also provide us the entire development process integration and even open the door to knowledge representation.
- Knowledge Representation and Software Automation . A more in depth analysis about this subject.
- Language Designers . Requirements of this new profile in sotfware development.
- Frameworks: the Better Half of Code Generation . Introduction and benefits of Frameworks and collaboration with code generation.
- Automation: the Whole Process . Compilation of the development process.
We will document more about our methodology in subsequent posts. Follow us on twitter (@Bheudek) to keep you posted on these and other issues.
View all Academic Posts.
View all Academic Posts.
Automation: The Whole Process
Throughout some posts we have been analyzing the different components of the methodology; we compile here the whole process.
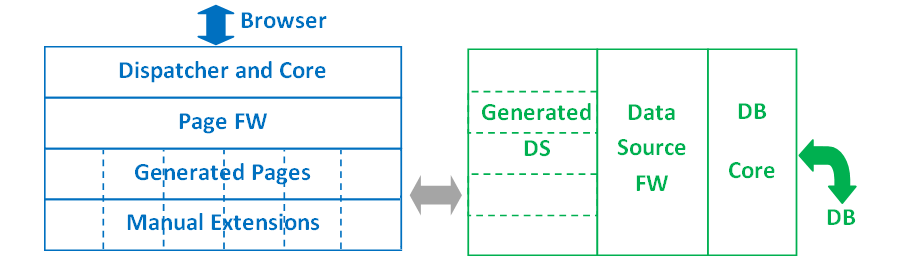
Code Generation
We will use the Language Workbench, once the languages (DSLs) are defined, to perform the programming process, and along this process we will generate code to compile it and check the result in the final application.
Whenever we use languages that support partial classes, abstract classes, generic types, delegates, etc., we can generate code safely because we will do it in separate files without risk of overwriting other code such as manual or FW code. In other kind of languages we will need to use other strategies to mitigate this risk.
Merging with Frameworks
As in the previous case, depending on the final language in which we generate, this process will be more or less simple. In the case of FW-friendly languages (abstract and partial classes, delegates, etc.), this merging process it is provided by the syntax itself.
In other kind of languages we will need to adapt some functionalities or some configuration files, which can also be automated by the LW.
Manual Extensions
In most cases there will be certain features that may not be automated; otherwise our DSLs will be too complex, losing, as a result, their power.
In order to integrate the whole process on the LW, the best scenery is defining these extension languages on it, but, If this is not the case, we will program these extensions in the final language where we generate the code.
If we program the extensions in the final language, the most suitable way is to give the generated code a FW structure. With this extensible approach we avoid the risk of loss or replacement of the code.
Code Generation
We will use the Language Workbench, once the languages (DSLs) are defined, to perform the programming process, and along this process we will generate code to compile it and check the result in the final application.
Whenever we use languages that support partial classes, abstract classes, generic types, delegates, etc., we can generate code safely because we will do it in separate files without risk of overwriting other code such as manual or FW code. In other kind of languages we will need to use other strategies to mitigate this risk.
Merging with Frameworks
As in the previous case, depending on the final language in which we generate, this process will be more or less simple. In the case of FW-friendly languages (abstract and partial classes, delegates, etc.), this merging process it is provided by the syntax itself.
In other kind of languages we will need to adapt some functionalities or some configuration files, which can also be automated by the LW.
Manual Extensions
In most cases there will be certain features that may not be automated; otherwise our DSLs will be too complex, losing, as a result, their power.
In order to integrate the whole process on the LW, the best scenery is defining these extension languages on it, but, If this is not the case, we will program these extensions in the final language where we generate the code.
If we program the extensions in the final language, the most suitable way is to give the generated code a FW structure. With this extensible approach we avoid the risk of loss or replacement of the code.
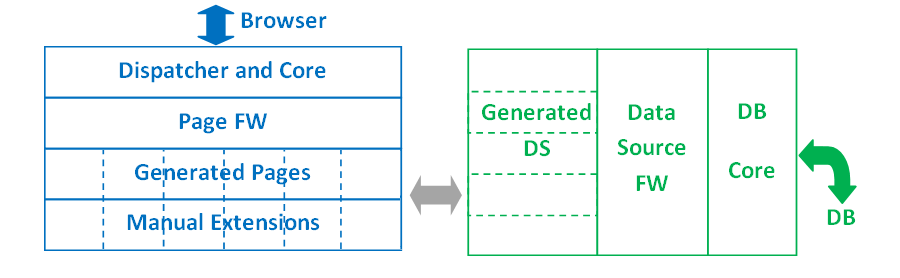
Components of the web server
Building
Once we have all the code: FWs, generated, manual extensions, configuration files and other, an automatic process performs the merging -if necessary-, the compilation and the deployment.
Depending on the operating system will have different tools to do it, but normally we will use batch files to program all the steps of this process.
In order to conclude, we want to remark that we have explained the methodology the way is done nowadays, but it is worth noting that it is a constantly evolving technology that aims to integrate the whole process in the LW: languages, debug, merging, building, etc.
View all Academic Posts.
Once we have all the code: FWs, generated, manual extensions, configuration files and other, an automatic process performs the merging -if necessary-, the compilation and the deployment.
Depending on the operating system will have different tools to do it, but normally we will use batch files to program all the steps of this process.
In order to conclude, we want to remark that we have explained the methodology the way is done nowadays, but it is worth noting that it is a constantly evolving technology that aims to integrate the whole process in the LW: languages, debug, merging, building, etc.
View all Academic Posts.
Frameworks: the Better Half of Code Generation
We define a Framework (FW) as a software structure with generic functionalities which can be adapted or extended in order to provide a specific application.
They can be mistaken with libraries but the approach is totally different. These are the FW key distinguishing features:
They can be mistaken with libraries but the approach is totally different. These are the FW key distinguishing features:
- Inversion of Control. The flow of control is dictated by the FW and not by the application using its services. This is also known as the Hollywood principle: “don’t call us, we’ll call you”.
- Extensibility. Certain functionalities of the FW are not “closed” – as it happens in libraries -, on the contrary they are designed to be extended in order to solve the particular problem.
- Default Behavior. FWs have a default behavior, which defines the flow of control. As seen before, the extensions allow us to adapt this default behavior to the particular problem that each application solves.
Frameworks are the base of plug-in architectures and software-ecosystem oriented systems (facebook, twitter, amazon…), but, above all, is the perfect base architecture for the generated code.
Technically, depending on the programming language, there are different ways to implement them. If it’s allowed by the language, abstract classes, partial classes, delegates and generic types are the best features to do it. Otherwise there are other strategies such as interpreters, intermediate functions – kind of visitor pattern- to solve the extensible call and others.
Benefits in code generation
These are some of the features that recommend the use of FWs:
Technically, depending on the programming language, there are different ways to implement them. If it’s allowed by the language, abstract classes, partial classes, delegates and generic types are the best features to do it. Otherwise there are other strategies such as interpreters, intermediate functions – kind of visitor pattern- to solve the extensible call and others.
Benefits in code generation
These are some of the features that recommend the use of FWs:
- Extensible. The work is divided in two main parts, which makes easier the definition of the code generator.
- Structured. Designing the generic part on one side and extensions on the other, provides a more structured architecture.
- Security. Handmade code and generated code are in different files, and this mitigates the risk of loss or replacement.
- Reusable. Once the FW is defined it can be used in different projects, again making easier the development of the generator.
- Readability. The separation of the generic flow of control and the extensions facilitates code reading.
Conclusion
When code generation is approached for the first time, it is often thought that the system must be 100% generated. After that, we realize that this is not only a complex approach, but also a design error and an unbalanced distribution of work.
To achieve a well-designed architecture and a good distribution of work frameworks are the better half of our generated systems.
Finally, it’s important to remark that designing the generated code as a framework structure is also a good practice, because it allows us to implement – by extending – those manually features that we don’t want to automate and it provides systems that can be extended by a software ecosystem.
View all Academic Posts.
When code generation is approached for the first time, it is often thought that the system must be 100% generated. After that, we realize that this is not only a complex approach, but also a design error and an unbalanced distribution of work.
To achieve a well-designed architecture and a good distribution of work frameworks are the better half of our generated systems.
Finally, it’s important to remark that designing the generated code as a framework structure is also a good practice, because it allows us to implement – by extending – those manually features that we don’t want to automate and it provides systems that can be extended by a software ecosystem.
View all Academic Posts.
Language Designers
Once you have a tool to design languages in an agile way, we face the most difficult task: designing them.
The designing of a good language is the main part of the process as it will be the tool of the developers and it will support the semantic intelligence of the system.
Furthermore, since the concepts of the language structure the model itself, before the design it is necessary to know deeply the domain being modeled.
Features of a good language
The designing of a good language is the main part of the process as it will be the tool of the developers and it will support the semantic intelligence of the system.
Furthermore, since the concepts of the language structure the model itself, before the design it is necessary to know deeply the domain being modeled.
Features of a good language
- High level of abstraction. The higher the level the more powerful will be the language and higher the semantic meaning of the concepts. Also, a high level of abstraction denotes a deep knowledge of the domain to be modeled.
- Simple. It should be easy to use and read. A simple language is often synonymous with a high level of abstraction.
- Different levels of complexity. While it should be simple, it should also allow ways to define deeply details by those who need it.
- Aesthetically pleasing.
- Semantically powerful. In order for a language to be productive, it is only required to provide its concepts with a graphical representation and translations to traditional languages, but if we really want it to be powerful, we must give the concepts other semantic interpretations: auto documentation, auto validation, inference rules, etc.
Requirements of a good designer
From the features of a good language we can derive the requirements:
From the features of a good language we can derive the requirements:
- Business oriented. Getting a deep knowledge of the domain, in order to design the language, requires a high concern in all the processes that govern it.
- Abstraction skills. Once the domain is known, analytical skills are required in order to identify, with the highest possible level of abstraction, its purest essence.
- Focused on semantics. The language has to be designed under the perspective of finding concepts with a high capacity to represent knowledge.
- Qualities focused on simplicity and aesthetics.
Conclusion
This new development paradigm requires a particular profile to design languages, where not only the former analytical skills are important but also the capability to provide usability and knowledge-representation capacity to the language.
At first, it may seem a complex task but, after all, is part of the evolution of technology where the profiles that contribute most are those with greater capacity for abstraction.
View all Academic Posts.
This new development paradigm requires a particular profile to design languages, where not only the former analytical skills are important but also the capability to provide usability and knowledge-representation capacity to the language.
At first, it may seem a complex task but, after all, is part of the evolution of technology where the profiles that contribute most are those with greater capacity for abstraction.
View all Academic Posts.
Knowledge Representation and Software Automation
Knowledge representation is a discipline devoted at representing the real world information in a way that can be interpreted by machines to solve, by inference, complex problems.
It has traditionally been an Artificial Intelligence subject and it has recently become very popular for its use in the field of semantics. The Semantic Web project, led by the W3C, is a clear example of it.
Although there are many approaches to represent the knowledge, all of them seek to define: the concepts, the relations and the rules that define the information. The different concepts allow us to classify the information and through the relations and rules we can infer (reason) from it. Therefore, instead of having only “flat” information we will have also meta-information to process it.
From the perspective of languages
In previous posts we saw how a language is defined, in a Language Workbench, by the abstract and concrete syntax and the static and dynamic semantics. We can see that definition as the meta-information that makes a program a knowledge representation and therefore we can use the potential provided by this discipline.
Usually Language Workbenches are seen as code generators but, from a knowledge representation and semantics point of view, they can offer many more services. We list some of them:
It has traditionally been an Artificial Intelligence subject and it has recently become very popular for its use in the field of semantics. The Semantic Web project, led by the W3C, is a clear example of it.
Although there are many approaches to represent the knowledge, all of them seek to define: the concepts, the relations and the rules that define the information. The different concepts allow us to classify the information and through the relations and rules we can infer (reason) from it. Therefore, instead of having only “flat” information we will have also meta-information to process it.
From the perspective of languages
In previous posts we saw how a language is defined, in a Language Workbench, by the abstract and concrete syntax and the static and dynamic semantics. We can see that definition as the meta-information that makes a program a knowledge representation and therefore we can use the potential provided by this discipline.
Usually Language Workbenches are seen as code generators but, from a knowledge representation and semantics point of view, they can offer many more services. We list some of them:
- Generate test batteries.
- Generate data population for performance analysis.
- Self-documenting.
- Auto-validation.
- Statistical analysis of the data and programs.
- Behaviour analysis of users, customers, etc..
- Simplify importing and exporting data. For example XBRL: eXtensible Business Reporting Language.
- Link with standard ontologies. For example FIBO: Financial Industry Business Ontology.
- Simplify integration with other systems.
- Machine reasoning.
Conclusion
 Knowledge representation is focused mainly on data processing: structuring search engines information, semantic analysis applied to Big Data, definition of ontologies related with different businesses, and others.
Knowledge representation is focused mainly on data processing: structuring search engines information, semantic analysis applied to Big Data, definition of ontologies related with different businesses, and others.
Software development methodologies that provide programs those capabilities are a gateway to the future with a huge potential.
View all Academic Posts.
Knowledge representation is focused mainly on data processing: structuring search engines information, semantic analysis applied to Big Data, definition of ontologies related with different businesses, and others.Software development methodologies that provide programs those capabilities are a gateway to the future with a huge potential.
View all Academic Posts.
Language Workbench
In previous posts we addressed what DSLs are and why they are useful and necessary in software development. Once we decided to base our development on them, we need a tool to design and use them. This tool is technically known as Language Workbench (LW).
A LW is composed of two main modules:
A LW is composed of two main modules:
- Language design.
- Use of the language. Programming.
Probably, in the future, it will split into two different tools, the reason is because, inside or outside organizations, there will be two different roles: language designers and language users (programmers).
Language design
A LW provides utilities to define the different building parts of a language:
Language design
A LW provides utilities to define the different building parts of a language:
- Abstract syntax. The grammatical/conceptual structure of the language. It’s also known as meta-model.
- Concrete syntax. The human-readable representations of these concepts. They can be textual and/or graphical representations. In other words, it’s the definition of the visual interface for the developers.
- Static semantics. Define rules and restrictions that the language must conform (besides being syntactically correct).
- Dynamic semantics. It is mainly the translation into traditional languages though, as we will mention later, here resides the greatest potential of this development methodology.
Use of the language
Once the building parts are defined, the tool is able to interpret them and provide a development environment (IDE). Besides editing, depending on how sophisticated is the tool, it can provide utilities such as: code completion, static validation, syntax highlighting, different views and even debug support.
This environment will also allow us to generate the code and, sometimes, integrates the target-application building process.
Future Potential
We could sum up that this new development process is similar to the traditional one but with the benefits of DSLs and code generation, which is the huge advance argued by researchers and supporters of this methodology.
Agreeing on this, for us the great potential, yet to be discovered, is the fact that a program is no longer a set of statements but a knowledge representation. Once we define the concepts and rules, semantics may be able to offer much more services than just code generation.
View all Academic Posts.
Once the building parts are defined, the tool is able to interpret them and provide a development environment (IDE). Besides editing, depending on how sophisticated is the tool, it can provide utilities such as: code completion, static validation, syntax highlighting, different views and even debug support.
This environment will also allow us to generate the code and, sometimes, integrates the target-application building process.
Future Potential
We could sum up that this new development process is similar to the traditional one but with the benefits of DSLs and code generation, which is the huge advance argued by researchers and supporters of this methodology.
Agreeing on this, for us the great potential, yet to be discovered, is the fact that a program is no longer a set of statements but a knowledge representation. Once we define the concepts and rules, semantics may be able to offer much more services than just code generation.
View all Academic Posts.
DSLs
Domain-Specific Languages (DSLs) are programming languages designed to define, in a more accurate and expressive way, particular domains, whether technical or business domains.
They are named like this as opposed to General Purpose Languages (GPLs – Java, C #, C + +, etc.), providing a narrower but more accurate approach. Their goal is: covering only the domain for which are designed, but with the most suitable grammatical structures and / or graphic abstractions .
Those languages can be analysed under the point of view of two different perspectives: as an evolution from code generation or as an evolution from GPLs.
From Code Generation to DSLs
There are different ways, more or less sophisticated, to generate code: macros, table-structured data, dynamic generation, parsing, CASE tools, etc, but none of them as powerful as a language (textual or graphical), which define, in a formal way, linguistic structures, human readable representations and semantics .
Therefore, we can see DSLs as the most powerful way of Code Generation.
From GPLs to DSLs
GPLs are powerful because they can be used to solve all the problems (Turing Complete) but in many cases are poorly expressive due to the big gap between the problem domain (real world) and the solution domain (source code). In those cases programming and maintenance is difficult because it’s not easy to understand (read and write) what the program tries to solve. For instance, we can compare the definition of a Web UI and its HTML code: the expressive gap is huge.
DSLs bridge those gaps.
Features and benefits of the DSLs
They are named like this as opposed to General Purpose Languages (GPLs – Java, C #, C + +, etc.), providing a narrower but more accurate approach. Their goal is: covering only the domain for which are designed, but with the most suitable grammatical structures and / or graphic abstractions .
Those languages can be analysed under the point of view of two different perspectives: as an evolution from code generation or as an evolution from GPLs.
From Code Generation to DSLs
There are different ways, more or less sophisticated, to generate code: macros, table-structured data, dynamic generation, parsing, CASE tools, etc, but none of them as powerful as a language (textual or graphical), which define, in a formal way, linguistic structures, human readable representations and semantics .
Therefore, we can see DSLs as the most powerful way of Code Generation.
From GPLs to DSLs
GPLs are powerful because they can be used to solve all the problems (Turing Complete) but in many cases are poorly expressive due to the big gap between the problem domain (real world) and the solution domain (source code). In those cases programming and maintenance is difficult because it’s not easy to understand (read and write) what the program tries to solve. For instance, we can compare the definition of a Web UI and its HTML code: the expressive gap is huge.
DSLs bridge those gaps.
Features and benefits of the DSLs
- Higher level of abstraction. They define more complex concepts, more abstract and therefore more intentional, more expressive.
- Less degrees of freedom. Normally they are not Turing complete. They allow to define the domain and nothing but the domain with the rules that govern the domain, which makes them very powerful (on that domain, of course).
- Productivity. Programming with them is efficient and more streamlined.
- Software quality. They abstract away technical complexity reducing errors. That complexity is usually solved by the generator.
- IDE Support. Validations, type checking, code completion, etc. This is a huge advance compared with abstractions via APIs or Frameworks.
- Platform Independent.
- And all the benefits of code generation.
DSLs are common in real life; throughout history they have been created in maths, science, medicine…Now is time to use them in software development.
View all Academic Posts.
View all Academic Posts.
